一致性哈希原理产生的原因及应用
在工程中,我们常用服务器集群来实现数据缓存,有以下常见的策略:
- 添加、删除、查询数据,都将数据的id通过哈希算法转换成一个哈希值,机尾key
- 若有N台机器,则计算key % N的值,这个值就是该条数据所属的机器编号,无论是添加、查询、删除操作,都只在这台机器上进行
很明显这种策略有问题,如果增加或减少机器数量,代价会很高,所有的数据要根据id中心计算哈希值,并将得到的哈希值重新进行取模操作,然后进行大规模的数据迁移。
为了解决这个问题,一致性哈希算法诞生了。
一致性哈希算法是一种很好的数据缓存方案。假设数据根据id进行哈希算法转换成的哈希值范围是0 ~ (2^32 - 1),也就是0 ~ (2^32 - 1)的数字空间,现在将这些书头尾相连形成一个闭环,在一条数据根据id生成哈希值后对应到环中的一个位置上。如下图所示: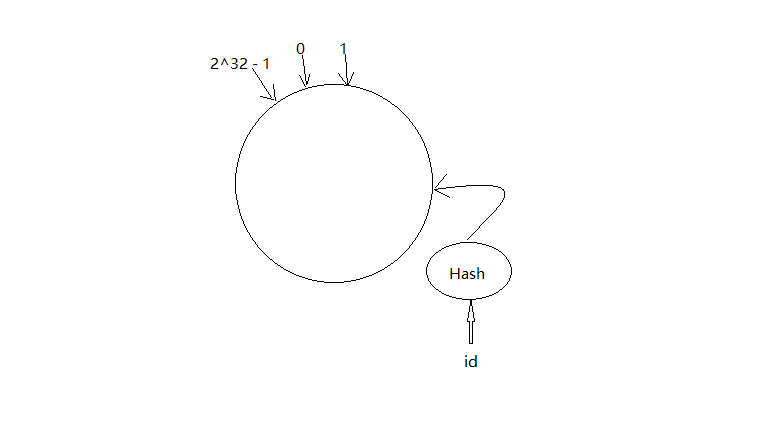
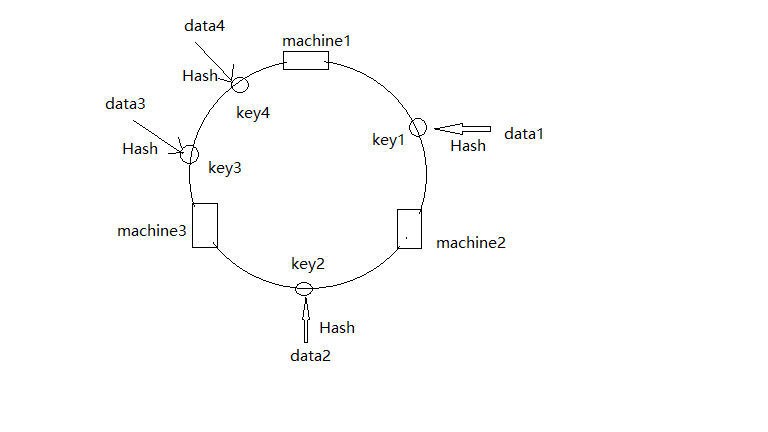
在图2中,data1根据id计算出哈希值key1,顺时针第一台机器是machine2,所以data1归属机器2,同理,data2归属machine3,data3和data4归属machine1。
增加机器是处理步骤
假设有2台机器和3条数据,数据和机器在环中结构如下图所示:
此时若加入机器m3,同时计算出m3的id在m1与m2右半侧的环中,这样加入m3机器后的结构如下图所示: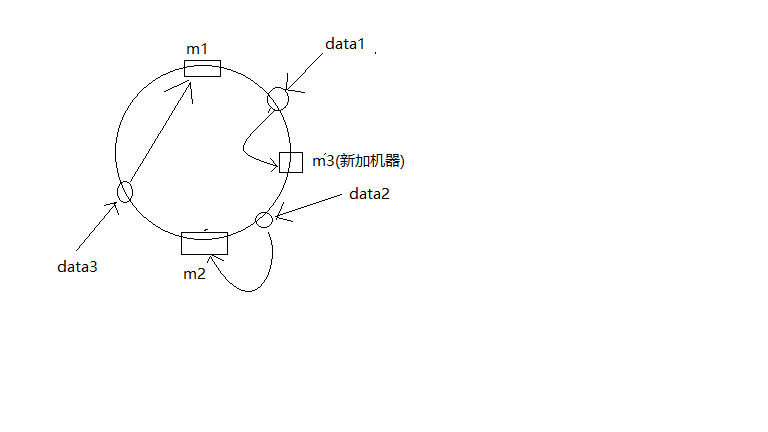
在没有添加m3之前,从m1到m3这一段是m2掌管的范围,添加m3之后则归属m3,同时要把这一段旧数据从m2迁移到m3上,由此可见添加机器时的调整代价较小。删除机器时也一样,只要把删除的机器上的数据全部复制到顺时针找到的下一台机器上即可,比如在图4删除机器m2,m2上的数据data2只要把它迁移到m1上即可。
机器负载不均时的处理,很有可能造成机器在整个环上的分布不均匀,从而导致机器之间的负载不均衡,如下图两台机器,m1比m2面临更大的负载。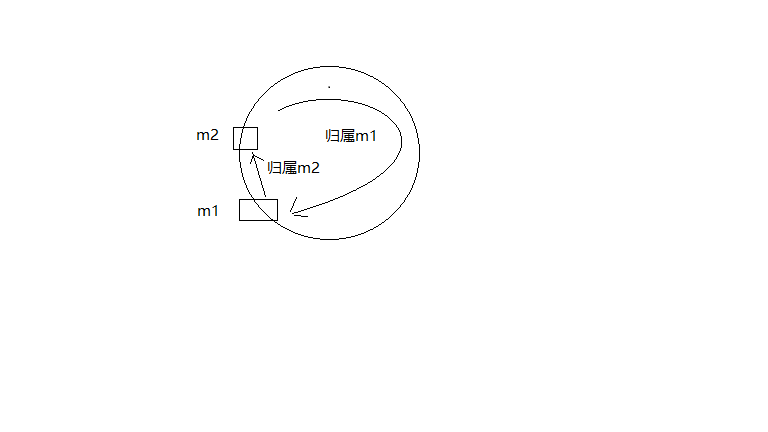
为了解决这种数据倾斜的问题,一致性哈希算法引入了虚拟节点,即对每一台机器通过不同的哈希函数计算出多个哈希值,对多个位置都放置一个服务节点,称为虚拟节点。具体做法可以在主机ip地址或主机名的后面加编号或者端口号来实现。如上图所示可以为每台机器计算两个虚拟节点 ,分别计算m1 - 1、m1- 2、m2 - 1、m2 - 2的哈希值,于是形成四个虚拟节点,节点数变多了,根据哈希函数的性质,平衡性会更好。
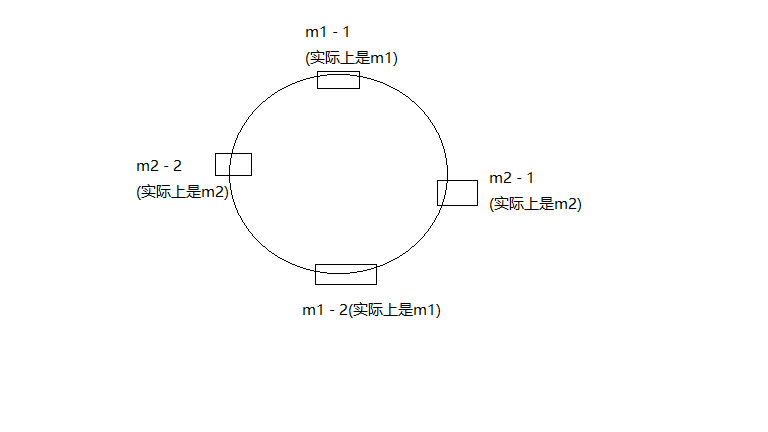
此时数据定位算法不变,只是多走了一步虚拟节点的映射,如下表

当一条数据计算出归属于某一个虚拟节点时,再根据上表的跳转,数据将最终归属于实际的机器;同样虚拟节点之间的数据迁移操作也可以根据上表的对应关系,变成实际机器之间的数据迁移操作。上述例子是给每台机器分配两个虚拟节点的情况。那么如果有三台机器A、B、C,我们给每台机器分配1万个虚拟节点,一共有3万个虚拟节点去抢占哈希环中的位置。那么在3万个虚拟节点中,有三分之一属于A、三分之一属于B、三分之一属于C,如果对外提供服务那么这三台机器实际上是负载均衡的。也就是说我们让每台机器分配较多的虚拟节点去抢占哈希环,数量多起来后,哈希函数的离散型就可以得到很好的体现,然后每台机器就可以按照虚拟节点的比例来分配负载了,这就是虚拟节点技术。